
Use cases
Financial privacy technologies opens up a lot of opportunities. There is more inspiration and ideas for better utilizing data than we can develop. A couple of use cases are listed below, of which some are validated algorithms and others are rough diamonds that need further exploring. Note that the use cases are part of research and co-exist with other existing initiatives.
Risk propagation
Each node has an initial risk score, determined by its bank. The score is predetermined, for example based on the amount of cash, cryptocurrencies or amounts from high-risk countries. The algorithm updates the risk scores of each node, using the (weighted) incoming scores in the transaction network. If a node receives a lot of money from a node with a higher (respectively lower) score, then its own score will therefore increase (respectively decrease). The following example might help to clarify this.
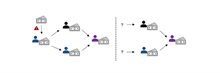
This is an example of a simplified money laundering pattern. In the left picture we see that a node receive a large sum of cash. This money is channeled through different nodes at different banks to the money laundering mastermind. The bank of the money launderer does not know about these cash flows. Risk propagation algorithm detects these suspicious money flows.
A scientific article written by TNO, ABN AMRO and Rabobank can found here: Privacy-preserving Anti-Money Laundering using Secure Multi-Party Computation (iacr.org)
Follow the Money
The goal of the Follow-The-Money use case is to allow for collaborative querying transaction data for specific patterns. For example, detection of cycles with a quick succession of transactions of similar amounts. This use case facilitates international collaborations and data sharing is reduced to a minimum on a per query basis, and using ephemeral pseudonyms that cannot be directly linked between queries.
Graph embeddings
Graph embeddings form a family of methods driven by the desire of applying machine learning on graphs, such as transaction graphs. Compared to other data structures, graphs are rich information: they contain information about nodes, links, local and global structure information. Common machine learning methods cannot easily handle such structured data and that is where graph embeddings come into play. Depending on the application, different characteristics of the node are highlighted, for example its own attributes, its local neighborhood or its role in the global graph. These vectors can then be used to apply standard machine learning methods on, such as linear regression.
Collaborative Feature Building
Each bank has aggregated data about how relevant different peer groups are in financial crime analysis, such as the alert ratio and the alert to true positive ratio. Examples of such groups are SBI codes, peer groups based on behaviour and accounts per region. However, banks do not know how these numbers compare to other banks. By securely comparing these numbers, banks can gauge whether they should put more emphasis on certain groups when performing financial crime analysis.
Secure Fuzzy Matching
Entities may have multiple accounts at different banks. These accounts may have small discrepancies between the information provided with the accounts, such as misspelling in names. By applying a (secure) fuzzy matching strategy, banks can link these different accounts to the same entity without revealing the data which differs. This information adds to the Know Your Costumer (KYC) information of the entity.